How We Survived Our Massive Flash Deal Spikes

Yesterday we just concluded our 48-hours non-stop every-item-10.000 IDR (<$1) flash deal marathon. Handling tens of millions of transactions is the norm here at Bukalapak, but those transactions are usually spread organically around the clock, so flash deals bring another level of challenge to our systems since the traffics are usually concentrated around specific time periods.
Behind the scene, several engineering teams have prepared for this event since a couple of months ago. This post is their story, their lessons learned, and the exciting joyride of doing live analysis of production bottlenecks and gaining 10x performance improvements with zero downtime to our users.
The Flash Deal
We split the flash deal itself into twelve "batches" of products. Every four hours, we introduce a new batch of product to our users. Users can take a peek at the next two batches to drum up the hype in advance. In total, there are hundreds of thousands of product inventories stocked for the flash deal. (Props to our fantastic Merchant Ops team for organizing this with tons of sellers all across Indonesia!) That said, due to the massive level of interest from our millions of users, each batch is typically sold out within the first 5-10 minutes.
The flash deal is app-only, which means our web users can only see the list of products sold during the flash deal, but they need to install our app to make a purchase. The benefit of using this strategy is that we can limit and control the path that we need to optimize for the event. Since Indonesia is heavily a mobile-first country, this strategy works without much hindrance to our users. The following screenshots are how the flash deal looks like for our mobile and web users, note the absence of the Buy button on the web platform.
The Prep
The first step in any preparation for high-traffic events is to define the performance envelope that we want to target. Since we never do any high-discount flash deals before, we are in the dark concerning what kind of reasonable target that we should pursue. In the end, we set our baseline target to 40x of the regular traffic levels, with any additional capacity beyond that as a nice-to-have.
The second step is to execute stress tests to our systems to identify our performance bottlenecks and take steps to mitigate them. For this step, the Performance Test group at Bukalapak had executed several stress tests a couple of months in advance of the event, with our infrastructure and reliability engineers carefully collecting all relevant instrumentation data during those tests. Our product engineers then analyze the data with our architect and devise the refactors necessary to reduce those bottlenecks. Here is an example of one of the metrics that we observed and collected during the stress test:
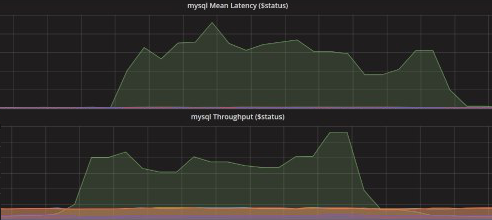
One particularly useful refactor, is to shift our "remaining stock" counter from our regular SQL database to a Redis atomic counter. Typically, for any given product, we update the stock by locking the row in our SQL database, update the stock, and then release the lock. This approach works fine because the likelihood of the same product being purchased by multiple users at the same time is rather low. (Especially since we have tens of millions of products in our marketplace)
However, for a flash deal event, where we can have tens of thousands of users frantically trying to purchase the same product at the same time, the lock-update-release approach can be an incredible bottleneck. This bottleneck is precisely what we found during our stress tests, where we simulate thousands of users trying to purchase a single product, and the update rates went down to low tens per second. By refactoring the stock for flash deals to use Redis counter pattern instead, we can handle thousands of concurrent updates per second with ease.
For each cycle of improvements, we ran another set of performance tests and collected more data about how our system behaves. In the end, we reached 50x capacity increase against regular traffic. Seeing that further improvements can take disproportionately more extensive time to achieve, and since we have reached our baseline target, we decided to deploy the system with a couple of weeks spare time before the event. We also added tons of instrumentation and metrics to the flash deal system, so that we can observe its heartbeat in production and quickly take steps in optimizing it during the D-Day.
The D-Day
We scheduled the launch at midnight of June 4th, 2018. As the clock turns to 00:00, dozens of automated alerts started to ring and load time spiked to tens of seconds. In those nerve-wracking seconds, we honestly thought the entire site went down, but then the automated recovery notifications started to pour in. Only then we are sure that the system survived the first wave of traffic spikes. The metrics started to pour in, and we saw that our users did successfully make their first flash deal purchases, albeit unbearably slow. Even then, the inventories for the first batch were sold out within 15 minutes.
That slowness is unacceptable, of course, so the team that's standing by jumped in to pour over all our metrics and instrumentation data to check what caused the site to slow down. We found several suspects and deployed our first set of optimizations within a couple of hours. It helps a lot that we have built the capacity to deploy any time to production, automatically rolling out updates to thousands of servers within 45 minutes, and with zero downtime to our users.
When the second wave arrived at 4 AM, the traffic has also considerably increased since we are currently in the middle of Ramadhan and a significant proportion of our users are awake from 3 AM for their sahur breakfast. We experienced another set of slowdown, but much less than the one we had during the first wave. More than 95% of our users can now load the flash deal checkout screen within five seconds instead of the twelve seconds that they previously had.
Making our flash deal checkout loads 2.4x faster is great, but five seconds is still unacceptable, so we had another round of deep dive to our metrics and instrumentation, and realized that the bottleneck now shifts to three parts of the code that did a query to our database. Two out of the three queries are relatively static in their results, but the third one can change a lot in short period. We decided to put a cache with fast expiry time for all the three queries. Users can see stale data for several seconds, but that should be fine since during the final part of the checkout step the data is being queried again to ensure the actual availability of the flash deal product. We then added manual sharding to the cache keys to spread the load around when we try to fetch the cached value.
We deployed the improvement and cautiously waited for the next wave, which can have even more traffic because it starts during the daytime. When the wave came, this happened:
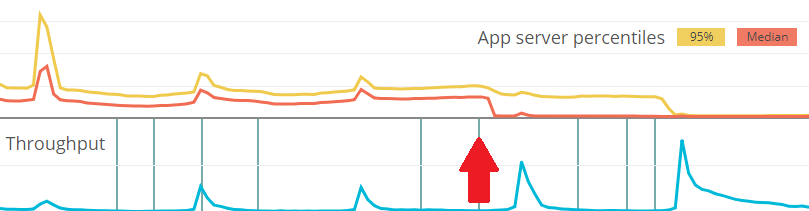
The red arrow is when we deployed the addition of the query cache to our flash deal system. The cache worked wonders and lowered the load time for the checkout screen to less than a second (with network latency added to the roundtrip) for more than 50% of our users, but the 95-percentile is still around two seconds. We then scaled up our cache cluster and tuned the timeout setting for the client, which brings down the 95-percentile to the same level as the median, even during the ever-increasing spike in traffic. At this point, we decided that the performance and reliability are now good enough for our users, and moved to passive observations of the flash deal metrics.
The Aftermath
In the end, we have no more significant hiccups during the rest of the flash deal. We managed to survive the event, and we are glad that and our teams can learn a lot from the ordeal. Kudos to the couple dozen engineers that have poured their effort so wholeheartedly these past several months, and cheers to the merchant team for organizing the event and working so closely with us along the way.
That said, we still keep a realistic view on the challenges and paths ahead of us. We had past issues in keeping up with our rapid scale-up, and unlike other online market sectors in Indonesia, the e-commerce market is still far from saturated, so we can expect sustained scale up like we had the past several years to project well into the next decade.
But with each learning opportunities like this, we believe we are moving one more step in the right direction. Even one day after the event, our teams are already moving towards analyzing the treasure trove of traffic and behavioral data generated from the flash deal to learn how we can better handle these kinds of events again in the future.
There is one more aftermath that I'd like to share, and I think this serves as an important reminder for us that, behind all those numbers and graphs, the collaborative efforts that we poured into the event are bringing powerful impact to actual human beings all over Indonesia.

What we see above is a single seller from Yogyakarta that received more than 3000 orders within the 48 hours of the flash deal. The seller is quite overwhelmed with the massive number of orders he received, but when the local Bukalapak seller community heard about his issue, the community self-organized and volunteered their time in droves (and free of charge!) to help him out. In Indonesian, we call this Gotong Royong, and this is a touching example that its spirit is still alive and well in Indonesia.
The Lessons Learned
Judicious application of cache for your queries can help a lot in managing existing traffic, which seems obvious in hindsight, but knowing which part requires this cache and what kind of cache behavior is acceptable is something that we can only predict but never know for sure until we encounter it in production. In our case, we have added several caching layer in other places of the system, but hesitant to add a cache for a query that can rapidly change. Only after observing the behavior in production, we can determine a safe expiry time for a useful cache at that particular location.
Another lessons learned is that stress testing our systems is critical to ensure our resilience against incoming traffic and to find out possible bottlenecks in a dynamically evolving system. (And with more than 700 improvements deployed every month to our systems, it can be very dynamic indeed) We originally focused our stress tests on the obvious bottlenecks, but in retrospect we should also try to run our stress test simulating the overall load for all the existing endpoints of the system.
The Obligatory Pitch ;)
If the above sounds like an exciting learning opportunities that you want to learn firsthand, we are always looking for more tech talents to join our engineering family. We have built one of the best tech workplaces in Indonesia, where we combine strong learning culture, mutual respect, and amazing positive impact on millions of Indonesians. This year alone we're on track to hire more than 300 new tech talents to help accelerate our growth even further. Sounds interesting? Check out our career site, we have tons of interesting roles!



Comments ()